Discover your web instincts!
Introduction :
Wikispeedia is an online game created by Robert West for the purposes of data science research, using a subset of articles from Wikipedia.
For every game, you are given two articles, starting from the source to the target by only following the links that appear in the articles you encounter.
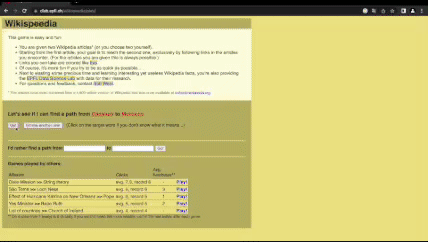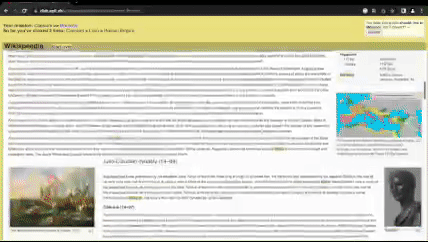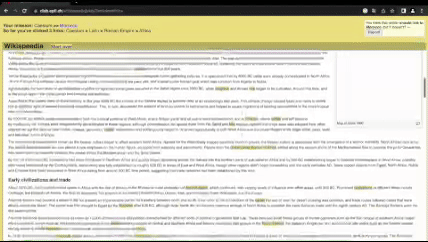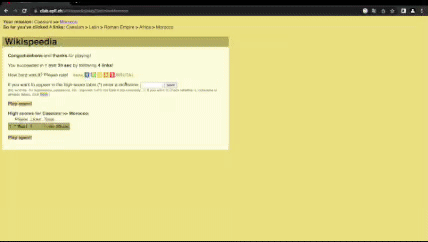
Navigating Wikispeedia is a lot like going through a maze. How would you for example link
Bacteria to Football or an Asteroid to Vikings ?!
In this story we will show you that:
Your instinct is your only friend !
Dataset :
The dataset provided by Wikispeedia contains paths found by players, of which 51318 paths got to their target and 24874 didn't.
It also contains all the articles, their full HTML package and the links between the articles. It is a hyperlink network of a 2007 version of schools-wikipedia.org [1]. For our research, we opted to discard all unfinished paths as they can be meaningless. We also removed paths containing backclicks as they do not represent the first human instinct.
All in all we have:
4598
Articles
119769
Links
15
Topics
To better visualize our data, we decided to create two distinct graphs out of the raw data. We start by creating the truth graph which contains all the articles and their links, this will also allow us later to find the shortest path between 2 given articles using Dijkstra algorithm. We then use all the finished games paths to create what we call a common sense graph : a graph that encapsulates the players' choices and tendencies.
Both graphs are interactive, don't hesitate to play around with them
to discover how strongly related the topics are !
The truth graph
The common sense graph

Motivation :
From our graphs, we can see by the size of the nodes that 91% of the articles have been explored. The main difference lies in the links between the articles, where we can see some links being much more explored than others.
Almost all of the articles in the graph have been explored, yet players only clicked on half of the links !?
It is therefore worth analysing the number of links in the unexplored articles.
Indeed, a deeper inspection has revealed that only 420 articles over 4598 have not been visited.
In addition, the proportion of unseen links in these articles represents less than 5% of the total unvisited links. The majority of the unused links are thus in the articles that have been explored at least once.
Let's infer then why those links have been discarded by users ?
Research Questions 🔎 :
In explaining the differences seen so far, we have come up with 2 major components: human intuition and the truth graph architecture. Namely, we will attempt to answer these questions:
-
How much do the players rely on the semantic relationship? We believe the players try to pick links that are sementically as close as possible to the target article.
-
How does the architecture of the graph impact the choices of the players? We want to investigate if the players have an inherent bias to pick links based on the graph's architecture.

1. Everything has a meaning :
We start by investigating the way a player chooses an article. This choice is unsurprisingly not random and is related to the target article. Here's an example to test your own intuition;
Starting from cheese, how would you go to mars exploration rover?
-
Cheese -> Space exploration -> Mars -> mars exploration rover
-
Cheese -> Argentina -> Ocean -> Mars exploration rover
It's easy for a human to see the relationship between 2 articles, but how can we quantify this relationship? We start by using the BERT model, an NLP model that computes an embedding from a given word or sentence that we can easily compare.
On each article from a given path we calculate 2 metrics:
-
Title Similarity: the similarity between its title and the title of the target article.
-
Article Similarity: of the target article.content and the t he similarity between its content
For each unique game (a couple of start and end article) played, we find the optimal paths by comparing the mean similarity metrics of the players paths to the mean similarity metrics of Dijkstra. Paths show that on average the mean semantic similarity for humans is higher than the optimal paths by 4% for articles content similarity and 5% for title similarity.
We also find that the optimal path has a wider distribution compared to the players paths which shows that humans actively give meaning to the choices that they make while the optimal path has no such concepts.

To make our point clearer, we chose to show you the similarity evolution on some of the most played games !
We will average the similarity over all paths found by humans and do the same on at most 30 generated random but optimal paths.








The shaded area in these graphs represent 95% confidence interval on the mean similarity over all the paths from the same game, meaning the narrower the shaded area, the fewer paths were found.

2. A choice, but not only yours :
We have seen that the players tend to play the game using the semantics of the links, we will now see if this choice is affected by other factors. Namely, we will look for the effect of the number of links in an article and the position of the links.
For this analysis, we have found that there aren't enough articles with more than 70 links to make a significant analysis, by discarding them we keep 95% of our articles.
By comparing the number of links explored to the number of links in the articles, we can understand how limited the player's search is.
From the regression analysis we find that on average we discover 44% of the links.
Interesting ... but naive, let's dive more into details !


This can be done by plotting the proportion of explored links.
We can see that the exploration percentage starts off very high and decreases quickly until the 10 links point where it continues to decrease but at a slower rate until reaching a plateau at 45%.
This result explains why some links are not explored in our graph, this is further supported by finding the number of clicks on each link relative to its position in the article.

It is conspicuous that links at the beginning of the article are much more likely to be clicked than links at the end of it. In fact, links in the first percentage of the article are 3 times to be chosen than links at the 80% mark.

3. Putting it all together :
We have found so far that the choices that the players make can be characterised by factors that we can measure well!
Why not use these factors as features for a model to predict if a link will be clicked on?
We do this by finding articles that have been reached by players and that contain a final link leading to the target article.
For nomenclature clarity we will draw inspiration from the GREAT game of Chess and call failing to find the target link : Missed mate.
We found 10894 instances of missed mates and 42254 found mates.
Out of the 42254 found mates, some final links appeared multiple times in the same article.
This type of article can create a bias; so by being discarded, this leaves us with 21620 final links.
We then use a Random forest classifier that takes 4 features and predicts with 82% accuracy if the mate is going to be found or not . You can see the ranking of the features and their importances in the following figure:
Conclusion :
To conclude, human behaviour when navigating in unknown graphs, as complicated as it can be, can be described using properly chosen metrics. We have seen that players rely on their intuitive sense to relate subjects to eachother which helps them get to their objective. However, we can note that the players might be too impatient in their choices and could to find better links by looking further in the article. This knowledge could help build better articles to further enhance the sharing of information!